cleanupゲームにおけるippo, mappo, svoそれぞれの学習結果について
SVO(Social Value Orientation)
SVOにおけるエージェントの報酬 :
→ が大きいほどエージェントが受け取る報酬における他者依存の割合が大きくなる
- 報酬角の設定によってはMAPPOよりも報酬が発生する(0.000 ~ 1.500)
uv run scripts/train.py env=clean_up algorithm=svo algorithm.SVO_ANGLE_DEGREES="[45,45,45,60,60,75,75]"
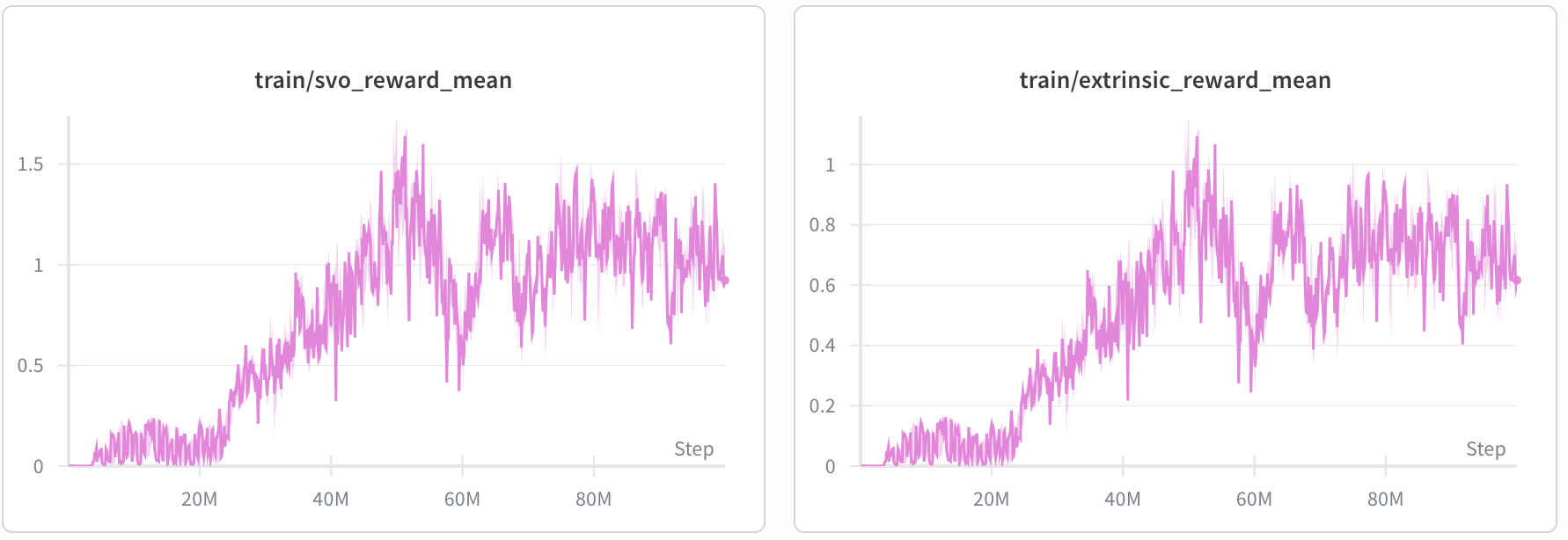
- 報酬角によって他者の報酬が流入するため、擬似報酬共有状態になる
- エージェントの振る舞いが報酬角によって分化する
- 社会ジレンマを扱っていると言えるのだろうか?